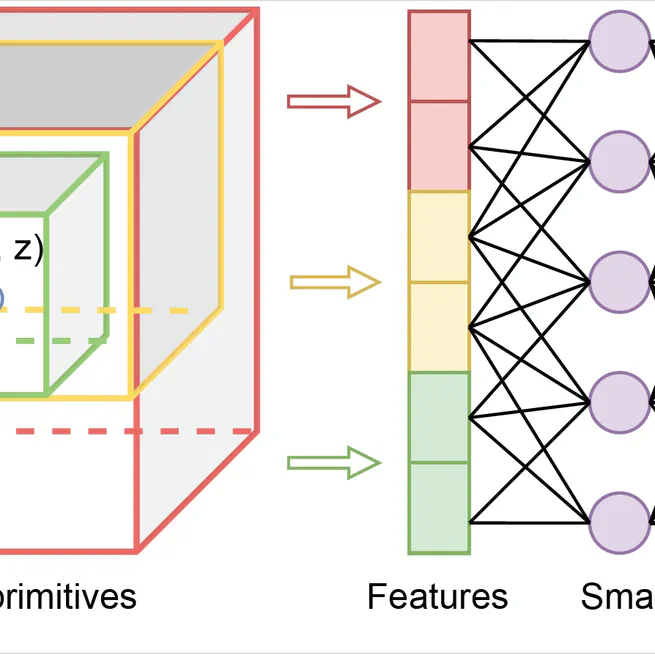
Neural Graphics Primitives-based Deformable Image Registration for On-the-fly Motion Extraction
In this study, we have successfully integrated NGP into DIR, a novel contribution that significantly enhances the accuracy and efficiency of medical image alignment as demonstrated on the DIR-lab dataset. The NGPDIR framework exhibits robust performance across various metrics, particularly in landmark alignment precision and the accommodation of anatomical sliding boundaries. This advancement not only propels the DIR field forward but also opens new avenues for real-time clinical applications, potentially transforming patient care with its rapid, reliable imaging capabilities.
Jul 8, 2024
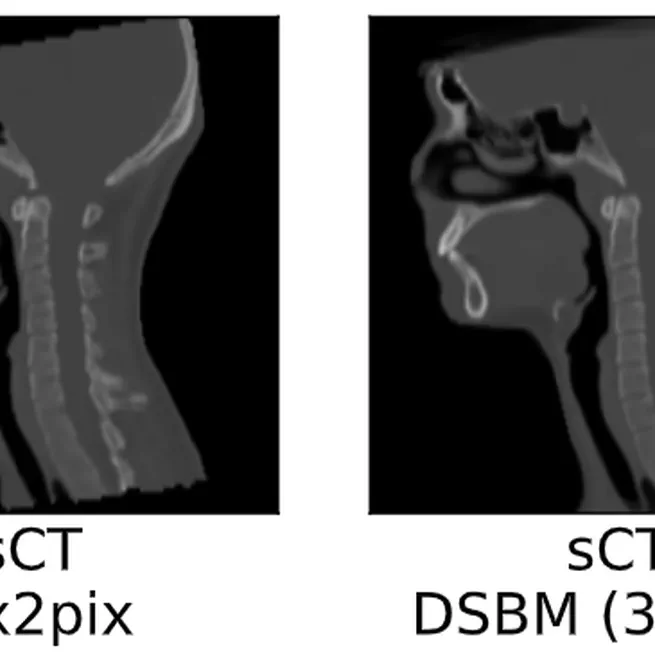
Diffusion Schrödinger Bridge Models for High-Quality MR-to-CT Synthesis for Head and Neck Proton Treatment Planning
In this study, we propose the Diffusion Schrödinger Bridge Models (DSBM) which enhances the performance of MRto-CT image synthesis, both in quality and efficiency. By learning the nonlinear diffusion processes between MR and CT data distributions and initiating synthesis from a prior distribution, DSBM outperforms traditional methods, as validated in our head and neck cancer case studies. This approach has demonstrated its value through comprehensive evaluations at both the image and dosimetric levels. DSBM can improve the accuracy and efficiency of MR-based treatment planning in proton therapy, which could potentially reduce imaging-related dose and improve patient outcomes in radiotherapy.
Jul 8, 2024
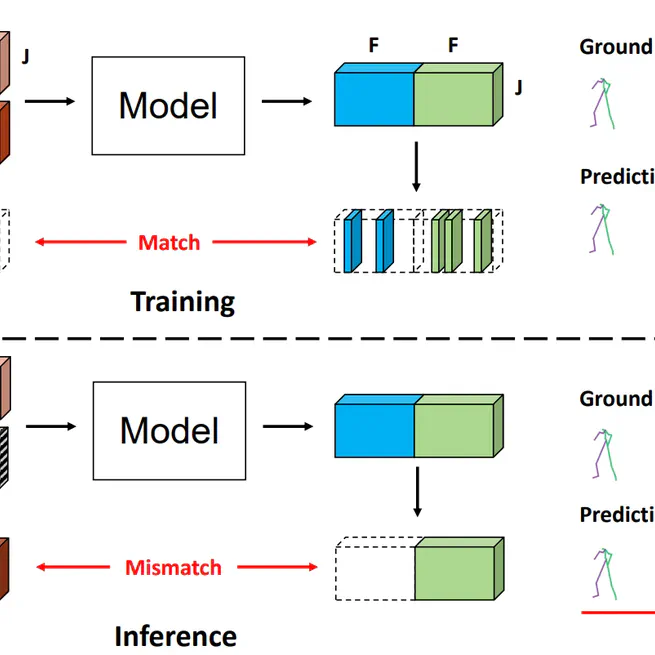
Skeleton-in-context: Unified skeleton sequence modeling with in-context learning
In this work, we propose the Skeleton-in-Context, designed to process multiple skeleton-base tasks simultaneously after just one training time. Specifically, we build a novel skeleton-based in-context benchmark covering various tasks. In particular, we propose skeleton prompts composed of TGP and TUP, which solve the overfitting problem of skeleton sequence data trained under the training framework commonly applied in previous 2D and 3D in-context models. Besides, we demonstrate that our model can generalize to different datasets and new tasks, such as motion completion. We hope our research builds the first step in the exploration of in-context learning for skeleton-based sequences, which paves the way for further research in this area.
Dec 15, 2023
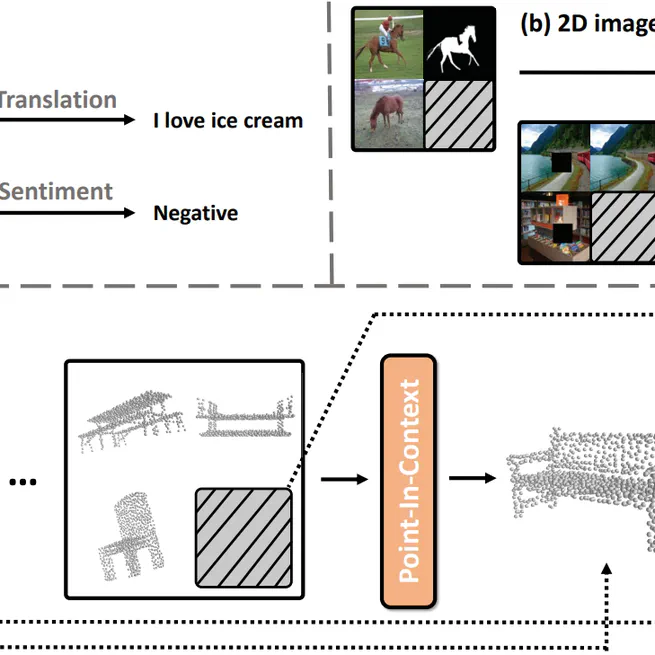
Explore In-Context Learning for 3D Point Cloud Understanding
We propose Point-In-Context (PIC), the first framework adopting the in-context learning paradigm for 3D point cloud understanding. Specifically, we set up an extensive dataset of point cloud pairs with four fundamental tasks to achieve in-context ability. We propose effective designs that facilitate the training and solve the inherited information leakage problem. PIC shows its excellent learning capacity, achieves comparable results with single-task models, and outperforms multitask models on all four tasks. Besides, it shows good generalization ability to out-of-distribution samples and unseen tasks and has great potential via selecting higher-quality prompts. We hope it paves the way for further exploration of in-context learning in the 3D modalities.
Dec 10, 2023
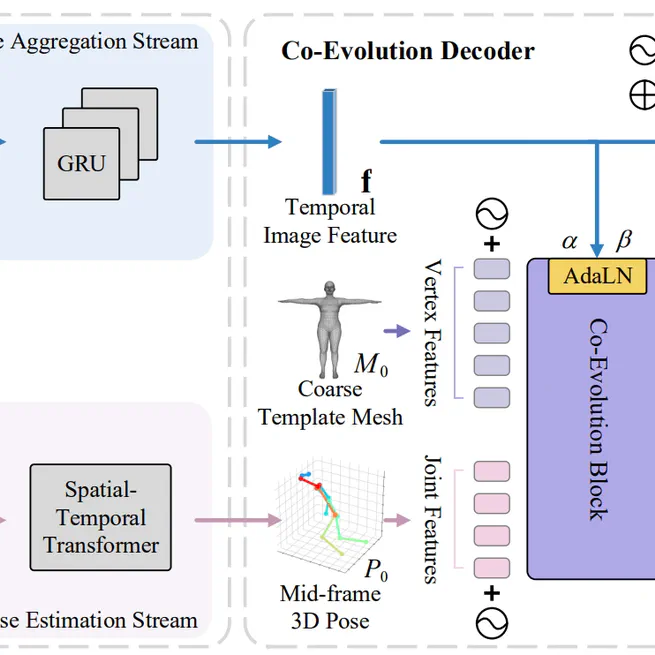
Co-Evolution of Pose and Mesh for 3D Human Body Estimation from Video
This paper proposes the Pose and Mesh Co-Evolution network (PMCE), a new two-stage pose-to-mesh framework for recovering 3D human mesh from a monocular video. PMCE frst estimates 3D human pose motion in terms of spatial and temporal domains, then performs image-guided pose and mesh interactions by our proposed AdaLN that injects body shape information while preserving their spatial structure. Extensive experiments on popular datasets show that PMCE outperforms state-of-the-art methods in both perframe accuracy and temporal consistency. We hope that our approach will spark further research in 3D human motion estimation considering both pose and shape consistency.
Oct 2, 2023
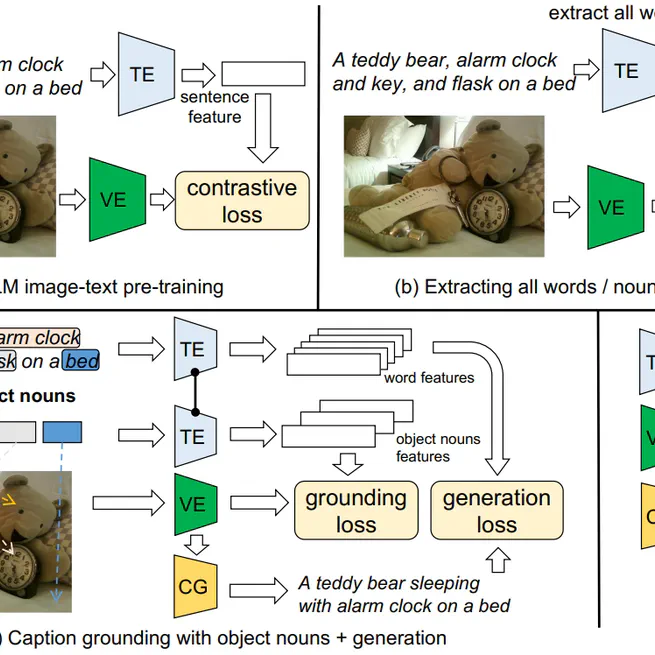
Betrayed by captions: Joint caption grounding and generation for open vocabulary instance segmentation
This paper presents a joint Caption Grounding and Generation (CGG) framework for instance-level open vocabulary segmentation. The main contributions are: (1) using fine-grained object nouns in captions to improve grounding with object queries. (2) using captions as supervision signals to extract rich information from other words helps identify novel categories. To our knowledge, this paper is the first to unify segmentation and caption generation for open vocabulary learning. The proposed framework significantly improves OVIS and OSPS and comparable results on OVOD without pre-training on large-scale datasets.
Oct 2, 2023
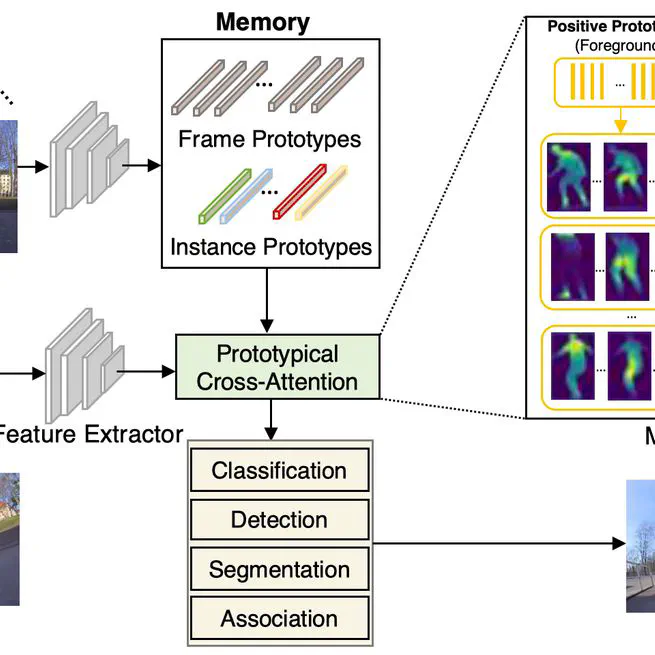
Prototypical Cross-Attention Networks for Multiple Object Tracking and Segmentation
We propose Prototypical Cross-Attention Network (PCAN), capable of leveraging rich spatio-temporal information for online multiple object tracking and segmentation.
Sep 12, 2021
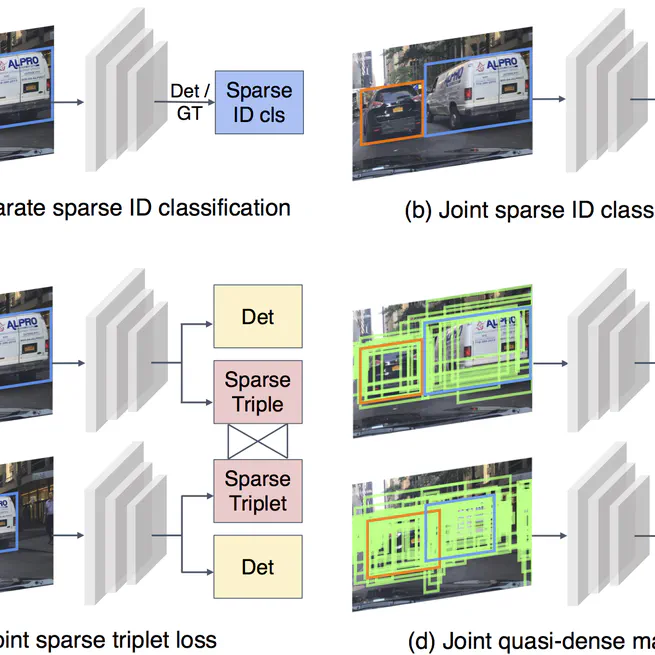
Quasi-dense similarity learning for multiple object tracking
We present Quasi-Dense Similarity Learning, which densely samples hundreds of region proposals on a pair of images for contrastive learning.
Feb 20, 2021
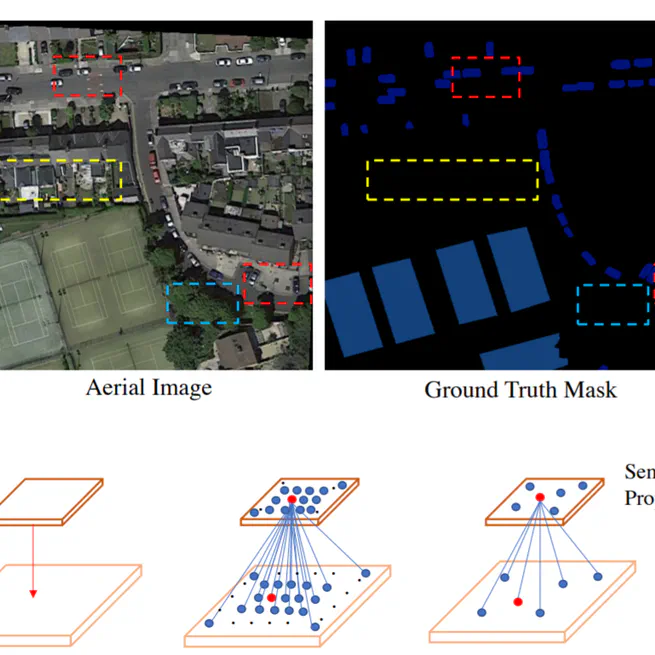
PointFlow: Flowing Semantics Through Points for Aerial Image Segmentation
Feb 13, 2021
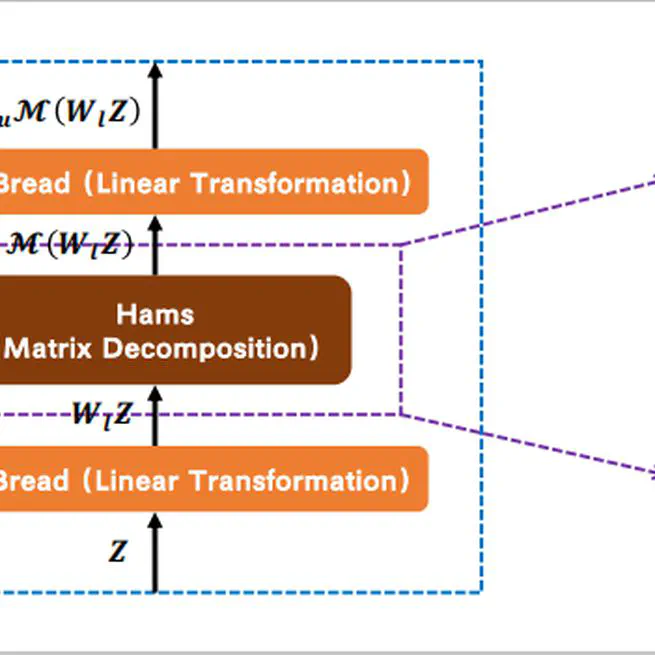
Is Attention Better Than Matrix Decomposition?
Self-attention is not better than the matrix decomposition~(MD) model developed 20 years ago regarding the performance and computational cost for encoding the long-distance dependencies.
Sep 28, 2020
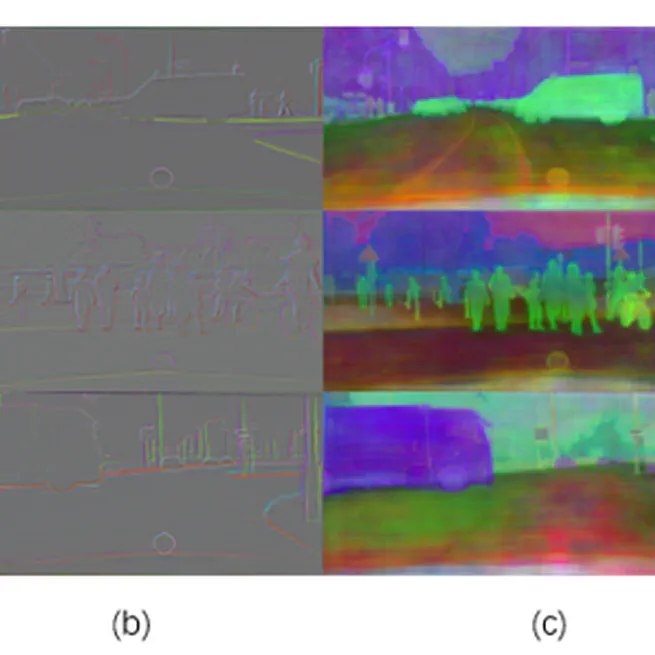
Improving Semantic Segmentation via Decoupled Body and Edge Supervision
Jul 3, 2020
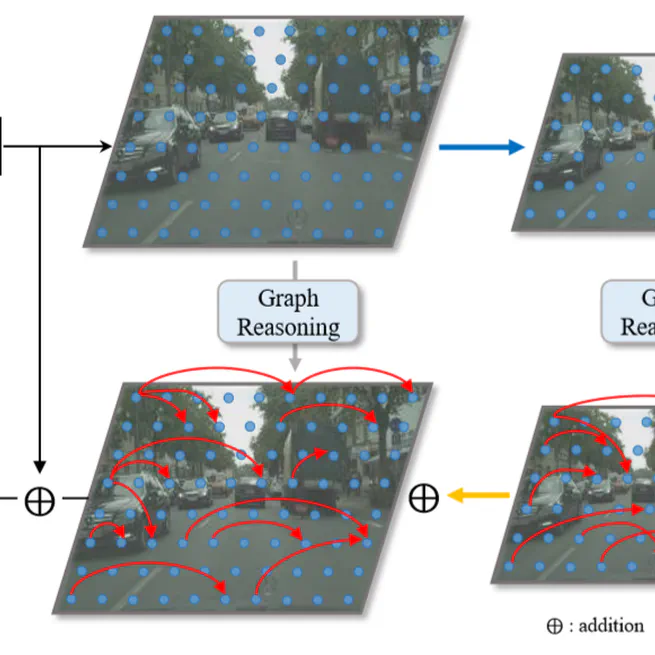
Spatial Pyramid Based Graph Reasoning for Semantic Segmentation
Feb 24, 2020
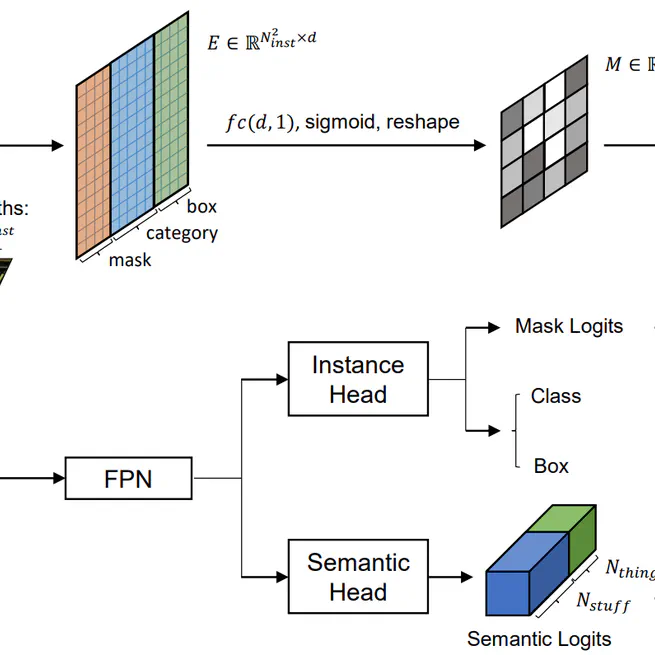
SOGNet: Scene Overlap Graph Network for Panoptic Segmentation
We leverage each object’s category, geometry and appearance features to perform relational embedding, and output a relation matrix that encodes overlap relations. In order to overcome the lack of supervision, we introduce a differentiable module to resolve the overlap between any pair of instances.
Feb 7, 2020
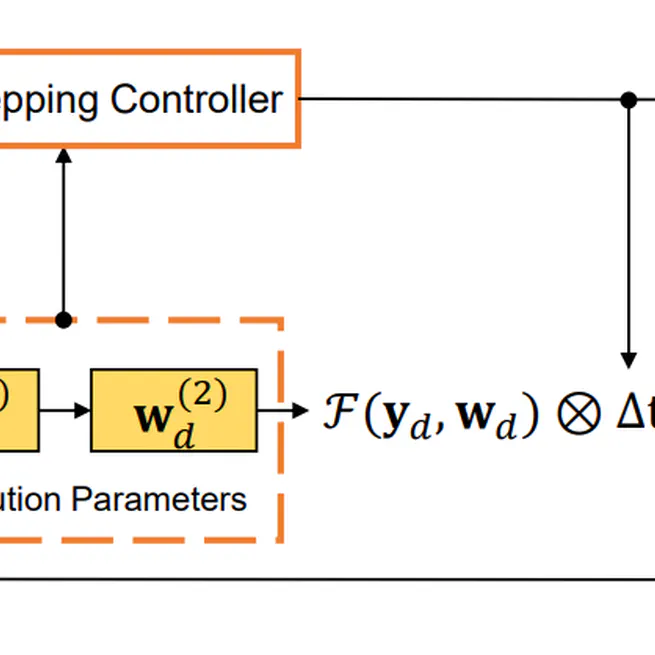
Dynamic System Inspired Adaptive Time Stepping Controller for Residual Networks Families
We analyze the effects of time stepping on the Euler method and ResNets. We establish a stability condition for ResNets with step sizes and weight parameters, and point out the effects of step sizes on the stability and performance. Inspired by our analyses, we develop an adaptive time stepping controller that is dependent on the parameters of the current step, and aware of previous steps.
Feb 7, 2020
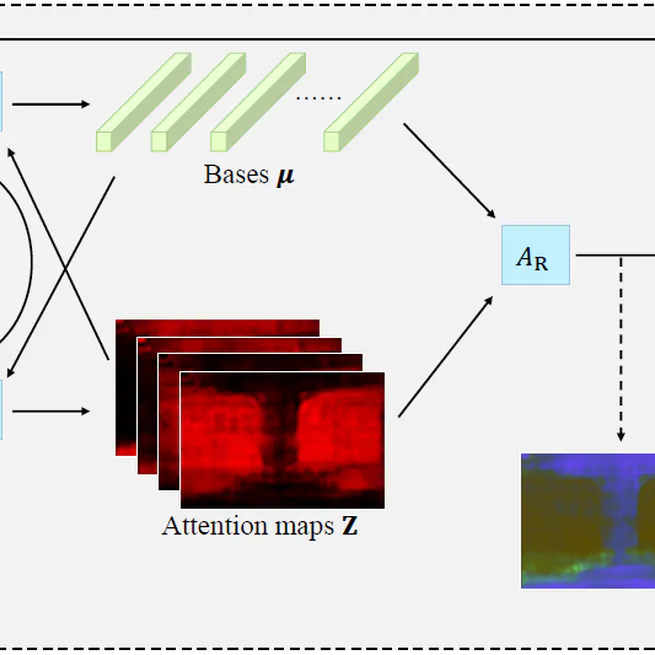
Expectation Maximization Attention Networks for Semantic Segmentation
We formulate the attention mechanism into an expectation-maximization manner and iteratively estimate a much more compact set of bases upon which the attention maps are computed.
Jul 22, 2019
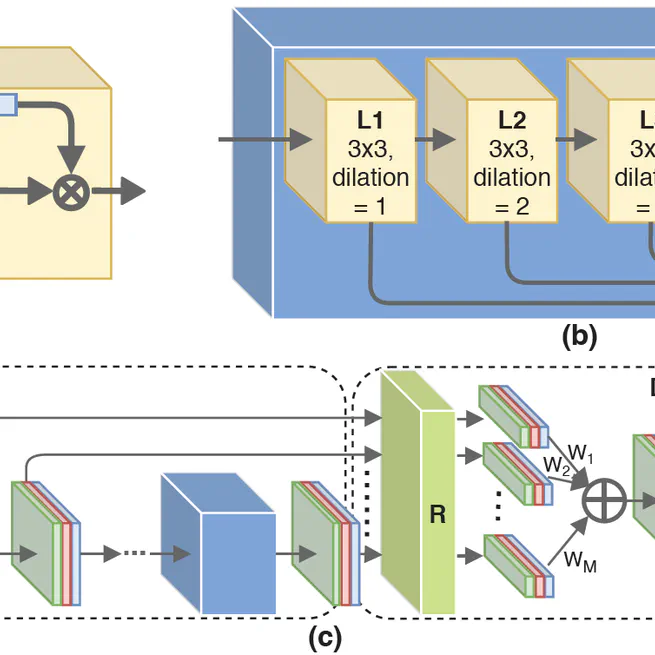
R^2 Net Recurrent and Recursive Network for Sparse View CT Artifacts Removal
We propose a novel neural network architecture to reduce streak artifacts generated in sparse-view 2D Cone Beam Computed To-mography (CBCT) image reconstruction.
Jun 19, 2019
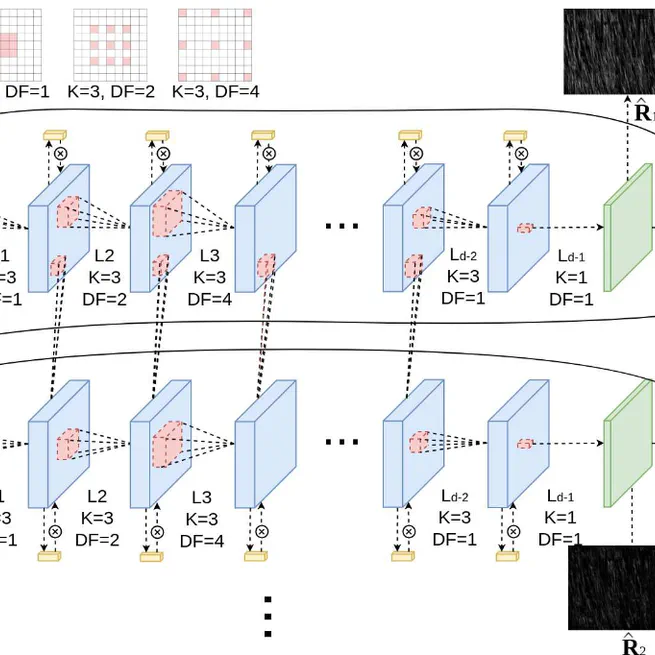
Recurrent Squeeze-and-Excitation Net for Single Image Deraining
We propose a novel deep network architecture based on deep convolutional and recurrent neural networksfor single image deraining.
Jul 19, 2018