Towards efficient scene understanding via squeeze reasoning
Jul 30, 2021·
 ,
,
,
,
,
,
·
0 min read
,
,
,
,
,
,
·
0 min read
Xiangtai Li
Xia Li
Ansheng You
Li Zhang
Guangliang Cheng
Kuiyuan Yang
Yunhai Tong
Zhouchen Lin
Abstract
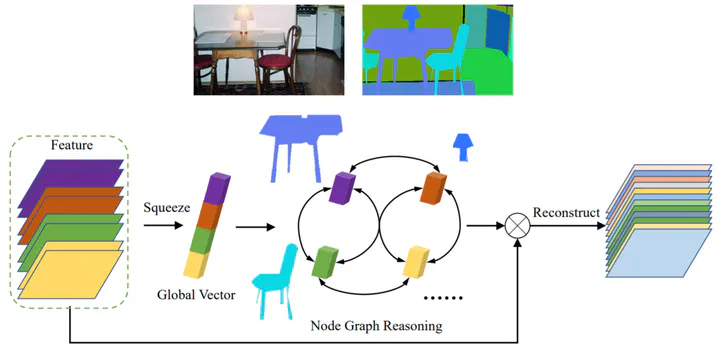
Graph-based convolutional model such as non-local block has shown to be effective for strengthening the context modeling ability in convolutional neural networks (CNNs). However, its pixel-wise computational overhead is prohibitive which renders it unsuitable for high resolution imagery. In this paper, we explore the efficiency of context graph reasoning and propose a novel framework called Squeeze Reasoning. Instead of propagating information on the spatial map, we first learn to squeeze the input feature into a channel-wise global vector and perform reasoning within the single vector where the computation cost can be significantly reduced. Specifically, we build the node graph in the vector where each node represents an abstract semantic concept. The refined feature within the same semantic category results to be consistent, which is thus beneficial for downstream tasks. We show that our approach can be modularized as an end-to-end trained block and can be easily plugged into existing networks. Despite its simplicity and being lightweight, the proposed strategy allows us to establish the considerable results on different semantic segmentation datasets and shows significant improvements with respect to strong baselines on various other scene understanding tasks including object detection, instance segmentation and panoptic segmentation. Code is available at
.
Type
Publication
IEEE Transactions on Image Processing