Explore In-Context Learning for 3D Point Cloud Understanding
Dec 10, 2023·
,
 ,
,
,
·
0 min read
,
,
,
·
0 min read
Zhongbin Fang
Xiangtai Li
Xia Li
Joachim Buhmann
Chen Change Loy
Mengyuan Liu
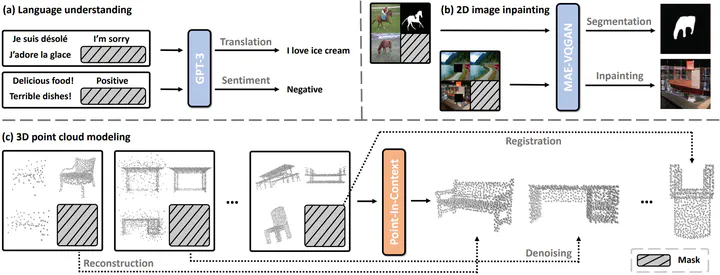
Abstract
With the rise of large-scale models trained on broad data, in-context learning has become a new learning paradigm that has demonstrated significant potential in natural language processing and computer vision tasks. Meanwhile, in-context learning is still largely unexplored in the 3D point cloud domain. Although masked modeling has been successfully applied for in-context learning in 2D vision, directly extending it to 3D point clouds remains a formidable challenge. In the case of point clouds, the tokens themselves are the point cloud positions (coordinates) that are masked during inference. Moreover, position embedding in previous works may inadvertently introduce information leakage. To address these challenges, we introduce a novel framework, named Point-In-Context, designed especially for in-context learning in 3D point clouds, where both inputs and outputs are modeled as coordinates for each task. Additionally, we propose the Joint Sampling module, carefully designed to work in tandem with the general point sampling operator, effectively resolving the aforementioned technical issues. We conduct extensive experiments to validate the versatility and adaptability of our proposed methods in handling a wide range of tasks. Furthermore, with a more effective prompt selection strategy, our framework surpasses the results of individually trained models.
Type
Publication
Advances in Neural Information Processing Systems