Abstract
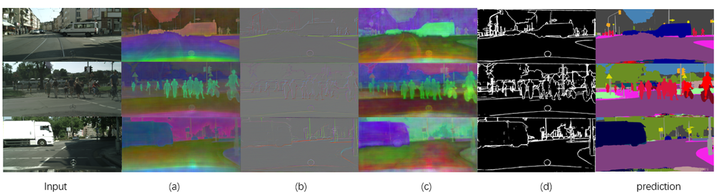
Existing semantic segmentation approaches either aim to improve the object’s inner consistency by modeling the global context, or refine objects detail along their boundaries by multi-scale feature fusion. In this paper, a new paradigm for semantic segmentation is proposed. Our insight is that appealing performance of semantic segmentation requires explicitly modeling the object body and edge, which correspond to the high and low frequency of the image. To do so, we first warp the image feature by learning a flow field to make the object part more consistent. The resulting body feature and the residual edge feature are further optimized under decoupled supervision by explicitly sampling different parts (body or edge) pixels. We show that the proposed framework with various baselines or backbone networks leads to better object inner consistency and object boundaries. Extensive experiments on four major road scene semantic segmentation benchmarks including Cityscapes, Camvid, KIITI and BDD show that our proposed approach establishes new state-of-the-arts while retaining high efficiency in inference. In particular, we achieve 83.7 mIoU % on Cityscape with only fine-annotated data. Code and models will be made available for future research.